
TL;DR
This is post 1 of ? and it’s rather long and covers a wide range of general areas to get to the eventual point: software architecture and programming languages that provide reduced barriers for entry that automatically compile to clean, optimized, and highly parallelizable code that directly aligns to hardware is where we all should be wanting to go. None of this is new territory, its just now that we as a group are at again another inflection point in which we can actually do it. I can only think of the movie Ratatouille, “Anyone can cook“, where right now I believe “anyone can write performance code“.
Towards the end of this post I will open up and introduce the approach to a project that I’ve been thinking about over the last couple years and recently started working on. The follow-on posts will be more dev-log than rambling history and at this point I’m not sure how many there will be but count on another 2-3 that will follow this one.

You get HPC, and you get HPC, and you all get HPC!
Hardware and software conceptually go hand in hand… right? eh? just about any developer would cite some horror story that contradicts such a thing. That a small change to something perceived as ‘simple’ had a total meltdown of unexpected outcomes. My background is in game engines and I can tell you on hundreds of occasions of slight changes that have straight robbed performance. That in most cases, the “mouth isn’t listening to the brain” – e.g. our software is running about all but oblivious to hardware alignment and capabilities. Normally we associate our work at the abstract/conceptual level and live in our ‘safe space‘ of a set of known programming languages. I enjoy C#, I tinker with Python, and wish I could spend more time with Rust. In my case, and I think in most general developers cases, we get comfortable in a language and we really leave the rest up to the compiler. I’ve come to learn that a lot of us out there – including myself – struggle with fundamentally understanding the trade-offs our conceptual “high-level” code goes through as it takes it’s trip through the compiler. I would argue that a majority of us are oblivious to that effort. To be blunt this is just fundamental computing concepts and why we have compilers: to help with taking those concepts/abstractions and boil it down to pure mathematical logic that the hardware understands. I don’t want to do that work – I’m very grateful for those compiler people out there! I personally want to be in my little safe-space-tower and write my little safe-code and bask in all the glory of what the magical compiler does and then take credit for it! I think it’s time to maybe rethink that – I am speaking on behalf of us ‘average‘ developers out there.
This isn’t ‘New’
High Performance Computing (HPC) for all isn’t exactly a new concept. It’s been a hot topic among computer scientists, developers, academics, and tech giants for quite some time. The power of HPC is embedded in our everyday computers, but many developers and enthusiasts don’t tap into this potential, often due to its perceived complexity. I just don’t think that a majority of developers are actively seeking to harness these capabilities. Like me most days, I’m relying on the compiler to do a brunt of the work while I write the code I already feel comfortable in. Again, these concepts I’m going to pinpoint have been around for a long time and the utility of what you can really do with most any modern day computer is relatively still living in the slightly-gated scientific community. General developers, general students learning to program, and/or computer hobbyists don’t often grasp that they can also take advantage of these gains in compute power. I think a lot of the approaches to get to this point are overly complex in breaking down that information and/or sort of stuck in ‘where do you begin’ fatigue. I think that’s a reoccurring theme within how we’ve historically taught computer-science. I wish we had more transparent alignment to how what we call “our code” comes out the other end of the compiler, and importantly what if it could be just be fast as computationally possible? Entire industries are built onto these concepts, it’s Intel, AMD, ARM, NVidia, Apple, Google, Meta, etc. they are always working on this and I don’t want to over/under estimate that. Just pointing out that a lot of what we are taught and how we write a lot of our code is very linearly sequentially safe and most often than not it’s oblivious to the gains we’ve made on the hardware side. Just look at what Apple has done on the chip side: let’s take an idea that’s been out for a while, ‘remix’ it and then magically sell it as our own: their entire ‘M’ chip design is truly that; built onto years of scientific research and beautifully advertised to the general masses or what I consider just their approach to native HPC concepts. Not to Apple Rabbit hole, just an easy example I can think of that relates to sort of what I’m getting to: this idea of HPC for all, or as in Apple’s marketing campaigns: “Buy a new MacBook!”
Even Transformer Models and Slowly Getting to the Point
From my perspective it’s important to derail the conversation to highlight the efforts with ‘Transformer‘ models. Fundamentally how through a ton of vectorization (those glorious breakthroughs in mathematics) have given us advanced functional capabilities to do pretty magical things. While I’ve derailed this introductory post, just to point out something via that previous Wikipedia link: the references there goes back to the early 1990’s and through to current. In that Wiki, one article I want to point out is, “Attention is all you need” by Vaswani et.al 1. That body of work has been now cited via Google Scholar at 104,157 times (as of 1-9-2024) or roughly 40 times a day! That papers contribution, and one reason why it’s cited even more than Geoffrey Hinton (AI Godfather) work on Deep Learning2; the work by Vaswani et. al. gave us a big break in speeding up how we traditionally were building these big deep learning models. Prior to them introducing the ‘The Transformer’ we were building these models with what’s called a ‘recurrent neural network’ (RNN) and that architecture required a sequential sequence. Vaswani’s group introduced the attention mechanisms which gave us a way to process that data in a parallel non-sequential way. This concept lowered the barrier of entry to a wider range of researchers/groups and the iteration speed on Transformer models have been break-neck paced since. That hurdle to get it into more peoples hands was getting the work parallelizable. Even I can now run these smaller LLM models on my own single home GPU.
The advancements in AI Transformer Models and currently what Apple is doing with the M-Chip as a general concept, really go back to a time old problem: how do you break up concurrent constraints on problem sets. Even though AI has stolen the spotlight of recent, it’s been a long time coming in a lot of other circles on how to best slice and dice and/or to compress and decompress knowledge and, mathematically, still have it be valid. This ability to harness parallelization opportunities across compute architecture and thus: truly the point I’ve long winded been trying to get to, take an existing way of doing something, for example, writing high abstract level code and now magically that code is fast as machine capable via some existing controllable Single Instruction Multiple Data (SIMD) set of instructions and/or eventually multiple instruction, multiple data (MIMD) compliant. Don’t let me fool you – this happens sort of “auto-magically” already, depending upon how we write some of our current code – but in most cases unless you are actively writing the code that’s in a ‘native’ SIMD/MIMD fashion, most higher level languages don’t exactly give you direct access to do this and ultimately we are back to the compiler.
I recently came across this post that gets into the technical details on optimization for ‘Go’. What I want to point out is the performance jump, going from 1.4Million vectors a second to 7Million vectors a second or 530% increase by then writing in Go assembly. They then mention:
“Now, it wasn’t all sunshine and rainbows. Hand-writing assembly in Go is weird”
Camden Cheek: 3From slow to SIMD
Taxonomy: SIMD, MIMD, and ARM For All + slight Apple Crush
This all falls back to Flynn’s taxonomy which was proposed by Michael Flynn back in 19664 . Almost all of today’s super computers are utilizing one of these 4 high level classifications:
single instruction single data (SISD)
multiple instruction single data (MISD)
single instruction multiple data (SIMD)
multiple instruction multiple data (MIMD)Again – point to what Apple is doing isn’t ‘new’ it’s just how they are remixing it – to take full advantage of these concepts, mainly with their unified memory concept on their M-series chips. Apple, in their fashion, takes something that’s been around for a while and roughly condenses that (in this case) 60-70 years of research efforts into a user experience gain with their M-series design. NVidia does the same thing. There’s been waves of these attempts and a lot of this stuff was built up conceptually and physically in the rise of corporate data centers in the 1990s5. I, like others, think the recent rise in parallelization for everyone is really because it’s getting really hard and super expensive to build smaller chips. If you take an existing infrastructure architecture and just pivot on how the functional logic works you can still maintain a current business cycle, not start from scratch, but basically do what Apple did with their system-on-a-chip. They can now deliver better battery, run faster software, and through some serious engineering still run older backward compatible software via their Rosetta translator 6and have it still be fast.
Apple is just putting emphasis on what is considered ‘out of order execution‘ and they are embracing ARM fully. For more details on technical specs of how these things compare to what was previously done and what they did that’s unique, this blog/article, and this post greatly helped. There are some trade-offs with this, but for the most part this design bridges how we conceptually currently ‘program’ and takes that information and parallelizes it across their M-series architecture. This design aligns perfectly to where we’ve been going for a while and why everything coming out over the next decade will be going to some sort of ARM instruction set. For most of what I’m going to be ranting about is really just aligning our abstract high level programming language to SIMD/MIMD concepts – but give us the ability to understand that. To be transparent about it, pick operations that restrict operations when we need to keep sequence and relax those constraints when we want higher speeds: none of this is new.
I also am acknowledging that there are all sorts of other pieces that had to come together to get here, where finally this level of capability can be more accessible in the hands of this little ole simple/average developer-me! Don’t get me wrong – I could have been doing this a decade ago but it was really a nightmare and there are points where it still is.
As we rely more on companies and organizations like ARM and what Apple is doing I hope that we also end up with more libraries that give us more control over these concepts while equally making sure we don’t break things too much! I intentionally mention Apple because of their use of out of execution order because it relies on order of memory being adjacent to each other. To access one byte or block of memory has a cost, a pretty big one, to access adjacent blocks of data you would think it would add in cost… once we have that one block, getting the adjacent blocks is no actual added cost assuming we have a few threads laying around. This concept is well explained in Why Apple’s M1 Chip is So Fast at about the 7 minute mark. As well as you can find information about the speed of their initial m-series chips from the Production Experts website7. It’s also how I’m going to make this awkward jump to from this current blog ramble to why I think Unity still matters and keep an eye on Epic!
Unity and This Ramble Goes On!
I’m just going to focus in this on from my perspective: Unity and what Microsoft and .NET have been doing. The ongoing efforts have been stretched out over multiple versions of software updates and has expanded into probably decades of efforts from individuals who specialize in hardware, software, compilers, researchers in HPC, and to those writing libraries for us developers to piggy back on. Unity publicly showed off in November of 2018 a native built in approach to writing C# code that transferred over to the compiler in a SIMD fashion. They originally called it DOTS for ‘Data Oriented Technology Stack8‘. I am guessing they started working on this upwards of 1-2 years before the announcement, that they were closely aligning to what Microsoft was pushing forward on with their .NET runtime libraries and the Rosyln compiler. Unity didn’t flat out come out and say this, but internally their core engineering teams had to have been doing this behind the scenes. To go from what they had announced to what is now their ‘Entity System Component’ or ECS approach would require a lot of rework/rethinking and alignment with Microsoft. They’ve been overhauling their core-engine concepts through a few important software packages while also maintaining their “current engine”.
Not to mention as I write this Unity just announced another massive cut in their staff, one can only hope that their leadership sees the writing on the wall with ARM, what Apple is doing, and they double down on their ECS work. I think there are only us die hard Unity individuals still hanging on (guilty as charged) – and I hope that my reason for hanging on aligns with what I see within their engine development group. They are fundamentally aligning their core engine to be a direct data oriented engine and as of current, they are boiler plating a bunch of object oriented concepts to make it easier for us simple minded developers. Behind the scenes the Unity Engine is directly aligning to hardware optimizations that Microsoft is doing within their advances in compiler wizardry. If you then look at Unity and their partnership with Apple, as they both equally are at war with Epic, they are aligning to leveraging one way for us to write fast as f code. This is a serious game changer. My only worry is that the general everyday developer/user doesn’t fully grasp this behind the scenes transformation and it’s still ‘easier’ to write code the other way.
I can write code right now that will have hundreds of thousands of interacting items, render them, interact with them, and make sure performance metrics are well over 100 frames per second. This is absolutely a game changer for a lot of other communities.
John Shull
Epic and Unreal
There are others doing similar things and I have to bring up Epic and Unreal. As much as I love the ‘Unreal vs Unity’ game engine rants, I have to give credit where credit is due. Epic is doing some amazing things in all areas of their game engine but I think as of current they are slightly behind on their engine logic being able to approach massive scale. That being said, they are actively working towards something absurd! What they are working on is more ambitious and I think they can pull it off. In Epics case it’s an entire “new” language called ‘Verse‘. They are leaning hard into functional logic language (again been around for a long time), but expanding that to meet the needs of modern entertainment/games. What they are proposing is directly inline to the languages and architecture we as general developers should be leaning more into and I’m equally excited to see how this plays out – see this video in which Tim Sweeney breaks down what they are doing with Verse. He says something right at the 3:48 mark:
We don’t have the technology to scale up to support millions of players in a single session… but in the future we want to crack that, we want to put everybody together in one massive shared simulation.
Tim Sweeney
Data Oriented Design and Software Project History
Coming from an object oriented perspective and learning more about data oriented design patterns has significantly altered how I see problems now. Data oriented design concepts directly align with everything I’ve previously mentioned – and for those coming from server architecture and database design (none of this is new). I want to point to a reference that helped me through that process greatly, actually same body of work and two ways to access it: ‘Data Oriented Design‘ by Richard Fabian, you can find his work via his own online access, and then the published book.
I’m going to attempt at breaking down how I am taking a model written in one language and converting it over to this approach. I have some tools we’ve built that I think I can give away after I go through a University Disclosure and my plan is to open source most of the core libraries that I’m building in Unity for this effort. This will go down over a series of online posts hosted on my own website at first and we might move that over to a more direct project site but who knows! I expect it to take me through the second quarter of 2024 and I think I will be still refining things well into the end of 2024. I would expect a version 1 end result sometime in May/June given the pace I’m going currently and what other projects I have on the table. I want to try to approach this as general as possible and I will reference when I use ChatGPT to help condense my rambles and/or make the reading age approachable – so far I haven’t used it – so that way anyone who has some level of computer developing background who finds themselves looking for alternative approaches and/or stumbling into HPC concepts for the first time can find help.
I want to focus in on what’s been immediately challenging, why I hope more people explore these concepts, and really look to the next wave of programming languages and interactions within those systems. Where even our own personal devices will be able to run things for us and manage a ton of interactivity and be able to render said interactivity within an affordable hardware set. I will also dabble in the history of global synced database architectures and how almost all of this is just really ‘functioning programming‘ but fancier! Almost all of these advancements have been around in general query challenges for decades and cloud database systems have all sorts of answers we can learn from. I want to tap into what I see emerging from my perspective in this area, what works right now, how we go from one concept to another, and ultimately where I think this is going. I will try to cite as many people/books/research as I can, but I will guarantee that I’m sure to have missed most.
Modeling Religious Change
The Modeling Religious Change (MRC) project has been around for the better part of a decade. I won’t go into too many details here as I am not part of the core modeling team, but that group is based out of Boston University through the Center for Mind and Culture (CMAC). That group has done a tremendous job in condensing a ton of data and information to boil it down to a mathematical population model. That group has done a ton of academic grunt work and they have all sorts of publications and presentations about it. Through my day job and through a previous researcher there, I came to understand their project and was brought on a few years back to sort of explore and deliver on the scaling problem for them. Again. nothing new here, and there are a lot of existing resources and pathways that they could have taken but they opted to try me out! My job was to take a version of their model and see how far we could scale it and make it affordable to run. One approach has always been to scale via cloud services but these projects don’t have the financial capital to cover those approaches. So, what can we bootstrap and/or partner with other groups to come to a performance solution that anyone can run on their own computer is where I was at.
This opportunity presented itself in the end of 2019 early 2020 right along with Covid which heavily impacted the overall project goals from my perspective, but the core group still powered on through. As they were getting a working model out 2023-2024, I was now starting to be more involved with how their model currently ran. Going through that process and through the general project with my background in Unity has put me in a unique position to see how we can leverage recent advances in compute and game engine capability to build and deploy large agent based models (ABM). I now see a way-of-working that has emerged for me and I think it’s a path worthy of sharing.
Improbable
When I first was brought onto the project I wanted to see if there was anyone ‘new’ in this area that already had a software solution. Something that highlights what I’ve already rambled on about – a solution already in a wrapped box that let us scale really easy. In my initial exploration back in 2019/2020, I originally had spent a lot of time talking with Improbable. They had some serious architecture that would let me build a massive “single instance simulation” and equally have ways to provide graphical representation of this environment. I had an opportunity to get close to their US defense development team based out in Arlington VA and they were working on ‘secret‘ modeling projects that let us mere Unity/Unreal developers build insanely massive networked environments that could be utilized for all sorts of models, especially these ABMs. The team up there was also very interested in building large complex agent based models. They had some agencies looking to find more advanced real-time solutions to aid in some of their existing modeling & simulation tools. Improbable and I had a mutual goal in that we were all sort of trying to do the same thing but for different use cases. The team they assembled in Arlington was truly unique and onto something very special, they just needed more time and unfortunately that wasn’t on their side. The larger global improbable company, having a significant fall-through on some crypto related work/investments that were tied to FTX, had to cut costs and they decided to cut a lot of their defense project teams. Since then Improbable has down-sized significantly and they are focusing on similar tools but really leaning into entertainment and platforms for entertainment9. Same issues, I’d say less mathematical and behavior/society modelers, and more general application/platformer engineering developers to serve the needs of their ambitious meta-verse solutions.
As Improbable’s US defense group was shutdown – my go to solution went with it. So I had to pivot. I had a student at the time working with me who wanted to learn Rust – I had him work on some things in Rust that I think were pretty awesome and if I had more my time myself I’d love to have created a solution utilizing Rust. We both agreed that there weren’t enough larger libraries out yet that would make this approach any less easier.
So what is the core software for the project? Why was I looking at groups like Improbable? Why did I spend the last 25 minutes of your time rambling about Flynns Taxonomy and hardware/software solutions in this area? First off, thanks for getting this far, second off, I’ve done a lot of thinking, research, reading, sitting in zoom calls, talking with people half way around the world, talking with people whom I’m not supposed to mention their names, piecing together no-name high level government agencies who are also interested in similar tools (hmm)… all so you didn’t have to! No really, this is a condensed reflection of years of notes, links, emails, etc. roughly hundreds/thousands of hours of reading/learning and rabbit holing. I hope you can take my last 20-25 minutes of writing and appreciate some of that to get to the core use case now!
Agent Based Modeling and Software Behind MRC
The model behind the MRC project is currently written in AnyLogic which is written in Java. This model was developed and designed via CMAC and they’re extensive network of contributors and world renown experts from a vast array of backgrounds. Like many in this field, when it comes time to write/build your model you generally end up in sort of three fields: academic solutions from research projects and/or open source analytical libraries, use some existing paid analytical software suite, and/or build your own in some sort of programming language your comfortable with.
There are a lot of analytical packages out there but not as many that focus in on a specific field of modeling & simulation for ABMs. For those who are familiar with ABM, we tend to all have our own sort of niche way of working. I think there’s enough of us now familiar with NetLogo that we can all appreciate software like that but we also all understand that it has it’s limits as well. I am a huge fan of NetLogo so if you’re not familiar with it, but you’ve gotten this far, please-please-please check it out.
You also have some new cloud/internet groups coming in like Hash.ai, they are pivoting to collaboration tools but they have a pretty awesome cloud based simulation engine called hEngine . And small pivot: regarding advancements in next tier AI models: one of the current/next phases you’re going to see are the utilization of more advanced Agent Based Models running ‘real-time’ and/or in parallel to say another system and then syncing with other existing more traditional models to help provide better context to various scenarios. Think LangChain but doing even more stuff in virtual environments. The rich research behind ABMs provide so many wonderful starting points that I’m sort of surprised that it hasn’t taken hook yet within the bigger technology companies.
Back to that sort of misc. approaches: so what if you wanted to ‘build your own?‘ Well, with Python and R you really can if you have a strong mathematical background and you’re pretty handy with writing code, this can be done pretty cheap but usually you run into the same problems most people do… what if you wanted it to run with millions and millions of interactive connected items? A lot of these current options have issues scaling, and so now were back to the same problem again. This can get expensive. There are already some players in this space commercially. Improbable was one that I was really looking forward to, CAE is another company10 that is actively working in a similar space (they hired some of the Improbable people), Simio has been around for a while, and another one that has been around a while is AnyLogic.
Now this is before you get to the academic/research labs – of which there is an excellent solution in Repast! Repast was my immediate first decision to go to as it checks all the boxes for what CMAC was doing but like with a lot of these existing open science / research lab solutions / it can come with a steep learning curve.11 At the moment, my only hang-up on not utilizing repast was my own lack of immediate capability and confidence that I could deliver using it. I knew it had extensive research and funding behind it. I still think it’s probably the best solution (at the moment) and I do think even my approach within Unity is going to probably back-fire on me in a few months. Honestly pretty surprised none of the bigger tech companies haven’t aligned yet on that.
All of that being said, AnyLogic has emerged as a front-runner for a lot of industrial application users probably because they sort of let you do whatever you want within their graphical interface. There software is aimed directly at individuals who have a hybrid background in mathematics, probably have a core engineering degree, understand basics of object oriented programming, have used other misc. analytical software that’s aimed at scientific analysis and/or engineering, etc. AnyLogic is pretty straight forward to pick-up and is very robust. It can be boiled down to a modeling & simulation software interface that’s written onto Java Runtime. I would say their market is more for industrial use cases than human behavior models, but they give you the tools to sort of do any of them. They interestingly also have a scalable cloud version that can let you build massive models. The only catch with them is it’s really expensive to scale their models up as it’s proprietary software and their more advanced licenses aren’t cheap – I looked into one and it was roughly between $15-$25k and that’s before getting to cloud compute time, etc. The MRC model is written in AnyLogic. There are also versions of it in Python that were used for prototyping systems. How does one take an object oriented program written in Java with AnyLogic which then dumps everything into XML and get it over to something that is data oriented?
Any to Many – Reflection Nightmares
We wrote a small program that can read in an AnyLogic file, which is just XML, and it will let you navigate and jump around the parsed XML file.
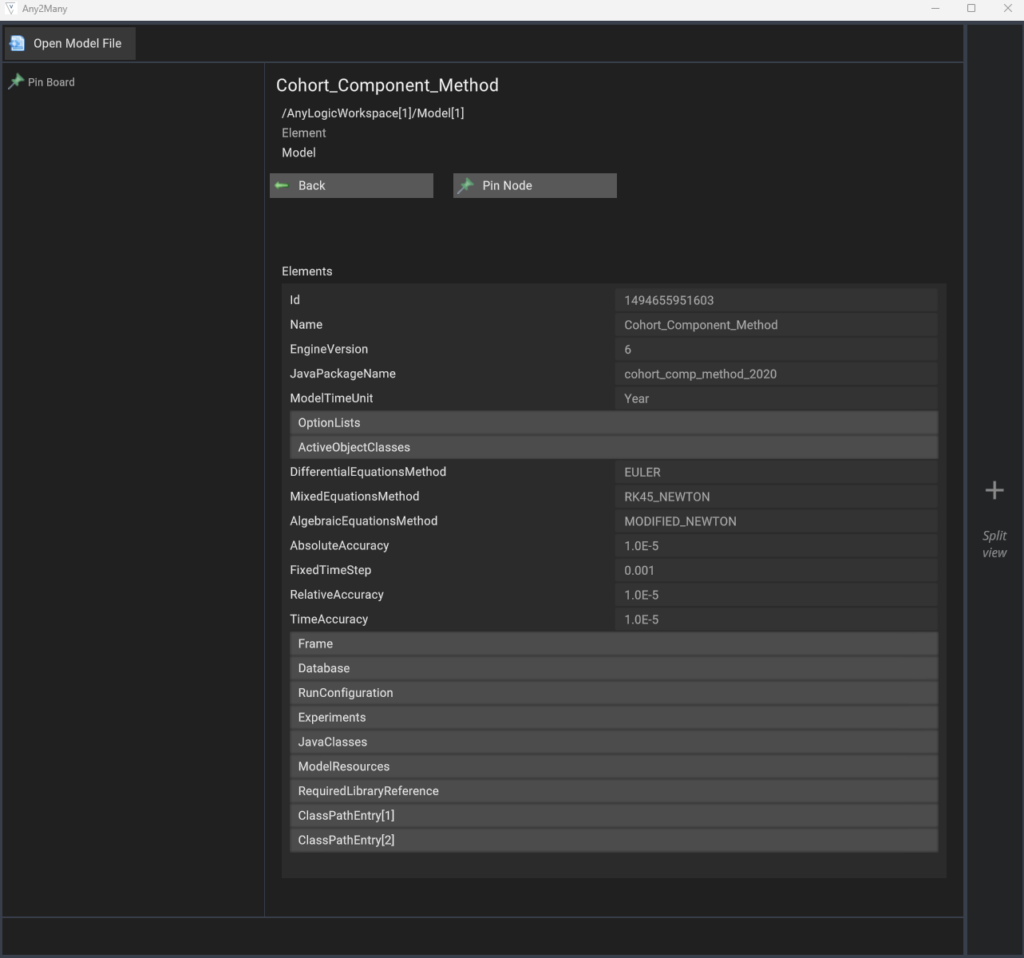


In the Any2Many software, it is a clean and simple GUI that just parses the XML file behind the AnyLogic model. In the image above we have loaded in one variation of the MRC Component ALP file. From here you can click on any of the light grey boxes to drill down into more information. For example we will drive down into the main agent node which is part of the ‘ActiveObjectClasses’ node in the ALP file.

Here we can see the two core elements to the node and if we drill down on main we will get the equivalent representation of that data object.

While under the Main node we can see ‘AdditionalClassCode’ in which if we click here we have direct ascii/text based access to be able to highlight, pin, and/or copy that information out in a much easier fashion.

If we now go into AnyLogic we can see the same information by navigating through their GUI. If you’re not familiar with AnyLogic I will spare you hours of details and will try to summarize them with a few pictures and explain how and where you can enter and write code.

I haven’t actually counted, but let’s assume there’s about 20 places you can write/enter code for your model. AnyLogic gives you this sort of top-down canvas in which you can drag and drop items into, you can connect them to other items, and you can do all sorts of fun GUI things here.

You can do your traditional scripting where you just write a Java script file and save it in the project. There are ‘agents’ which are fundamentally general objects but they have added in abilities (more areas to enter in code) that again you can assign scripts to, reference other GUI based items, or inject other code from other items by connecting them together. Their GUI system is great for people who don’t write a lot of code but when you start to hybrid it with a lot of code it becomes a sort of GUI-Code-Soup hell. AnyLogic is this massive interface and there are panels/windows throughout their interface that are hooked to these sort of objects that you can have little bits of code injected into them. This makes tracing code in AnyLogic more like a detective working a crime scene because of glorious Java reflection. AnyLogic is using reflection everywhere.
For example: you might be following along within their interface for a state machine. If you are just using their GUI and no actual separate script files then it’s pretty easy to navigate, but because they let inject wherever you want within their GUI, it can become a mess. Since AnyLogic is using reflection throughout there is a lot of overhead that comes with it. Managing this complexity becomes increasingly more difficult. You have a lot of compile-time checking that goes down so when you build vs run your model you will find all sorts of misc. errors peppered throughout that more Java standard features would have caught. I like to think that a lot of general programmers avoid heavy uses of reflection, maybe I’m wrong? I love it for serialization and deserialization but that’s what I consider ‘bumper lane reflection’ in which you can more easily catch issues. In general, reflection and the dynamic capabilities are necessary and without them we wouldn’t be able to run a lot of the software we have, but when you rely on it extensively in software like AnyLogic it can cause all sorts of chaos. You can break and crash these models in AnyLogic very quickly.

So if you decided to use the ‘On Startup’ portion of the state machine node to fire off something there isn’t an easy way to identify that unless you click through every single object in AnyLogic. In the example above the On startup is firing off a function called setInitialParameters. This function isn’t part of java file but instead another reference to a block of reflection based code.

It’s one thing to have sort of cumbersome libraries and various scripts within an IDE – as long as you can trace it through the IDE – you can resolve it. In AnyLogic trying to maintain a conceptual model of the work while also having reflection throughout the editor is a recipe for very complex issues that grow at scale. Since there is so much reflection being used within the editor, while you’re building the model itself, it can become a challenge to trace and keep tabs on where everything is. It’s a lot to keep in working memory, and if big events are in the reflection parts of the code base then when an issue does arise you have to come at it from multiple angles. I give AnyLogic credit for offering software that lets people build these models – but some of the behind the scenes traceability are painful and I blame the reflection piece of their software as being too much and I would greatly appreciate a “less is more” mentality as you get into the larger more connected models.
AnyLogic, Java, Datasets and Databases
You also have ways to connect your existing data – AnyLogic will let you import all sorts of different files and build tables under their “database” inside AnyLogic. This is super helpful for people who deal with a lot of CSV files and/or a lot of different data sources from different individuals. AnyLogic allows these tables to be directly linked to those sources so when you update the data you just tell AnyLogic to update the data on model startup. AnyLogic internally is using HyperSQL which is great for the internal functioning of their models but there are tradeoffs as you start to build larger models that have more concurrency needs. In my understanding of HyperSQL: data types are restricted which might be a good thing in some cases, but it means you have to spend some time getting external data into these types, but the biggest issue with HyperSQL is it uses a traditional locking-based approach. This can lead to reduced concurrency when you have large interactive agent based models and HyperSQL not taking advantage of the more modern approaches to multi-version concurrency control. In most cases HyperSQL is perfectly fine for a lot of medium models and in most of the AnyLogic industrial use cases it’s fantastic, but when you get to a lot of interactivity (lots of people talking to each other) and a lot of individual components/objects doing that interaction you’re going to be fighting it in the large/extreme cases.
AnyLogic as a system is based on Java. Java is a robust language but it’s OOP and garbage collection has serious costs when you get into millions of objects. There also was a long running issue internally to AnyLogic, they say they resolved it in November of 2023, but since it’s based on Java, there is a known issue called the ‘Java 64k limit’ error and AnyLogic hedge’s their language a lot in their updated blog post for version 8.8.5 which came out in November of 2023 . They are still suggesting that you will probably need to have an agent of an agent model to work with more complex agents – such an OOP thing to say.
To help – as mentioned above – our little ‘Any to Many’ tool made it easier for us to navigate these larger complex AnyLogic models and identify sections of code that were buried away in the GUI panels. We didn’t get all the way to building our own links/references but the tool helped us greatly explore the code base without having to fumble our way through the UI. In most cases we would run our tool on the side while the AnyLogic editor was open no another monitor. We then came up with a quick way to sort of typecast concepts in AnyLogic to a middle ground of native C# that would let us then get to an ECS model for Unity. That table is broken down below. As simple as that sounds and as straight forward as it appears – it took us a while to get to that point for us to standardize ourselves so as we go from one program paradigm to another we could maintain consistent connectivity back to the original core code in AnyLogic. Below is a simplified version of this where our solution called ‘Unity-ALP’ is maintaining similar naming conventions to align with the AnyLogic work. We then propose how that gets incorporated via the ECS column.
| Unity-DoD | AnyLogic | ECS | Notes |
| ActiveObjectClasses | Agent Types | SystemBase + Entity Archetype | Instantiated as entites |
| OptionsList | Option List | Enum / Schema File | C# Enums |
| Variables | Variables | ComponentData | Change at runtime |
| Parameters | Parameters | ComponentData | At start; do not change at runtime |
| StateChart | StateChart | SystemBase + ComponentData | Comprised of functions / states |
| Functions | Functions | Methods in static system classes | may also be member functions depending upon use case. |
| Transition | Transition | OnCreate/OnUpdate | most transitions become requirements for order of operations between ecs systems and/or if we need to maintain dependencies e.g. if we have to guarantee that one system finishes before another we pass that system as a dependency forcing the ECS engine to make sure it’s done before going onto the next stack of operations |
At this point I think it’s good to pause here and begin the next series of posts as I have now provided most of the ‘thinking’ part of this project and even dabbled a little on the development side to set everything up. In the next post I will be breaking down the major systems of the current AnyLogic model and their equivalent representation on the Unity-DoD side.
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017). ↩︎
- Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems 25 (2012). ↩︎
- Slow to SIMD ↩︎
- M. J. Flynn, “Very high-speed computing systems,” in Proceedings of the IEEE, vol. 54, no. 12, pp. 1901-1909, Dec. 1966, doi: 10.1109/PROC.1966.5273. ↩︎
- https://semiengineering.com/the-rise-of-parallelism/ ↩︎
- TopTal ↩︎
- Apple m1 so fast ↩︎
- Unity Unite 2018 ↩︎
- Improbable to Sell US Defense ↩︎
- CAE Defense Security ↩︎
- Repast Documentation ↩︎